DOOR analyses are claimed to be more patient centric. Instead of constructing summary measures by group for each outcome, the DOOR approach combines endpoints at a patient level and then creates a summary measure of the composite view for each intervention.
There are two approaches to a DOOR analysis, see [1]. The first approach uses the pairwise comparisons as introduced in Mann-Whitney-U. However, unlike the classical MWU, in the DOOR analysis, all the paired results are incorporated into the test statistic (this can also be done in MWU but wasn’t discussed in the earlier post). The other method used for the DOOR is a partial credit approach, but I do not really understand what that is about.
As a result, the DOOR analysis gives you an estimate of the probability that a randomly selected patient in the experimental group will have a better ranking than a randomly selected patient in the control group. The calculation used for the aggregated pairwise comparisons is:
where \(n_{win}\) is the number of times the units in the experimental group had better outcomes compared to the control group, \(n_{tie}\) is the number of ties, \(n_e\) is the number of units in the experimental group and \(n_c\) the number of units in the control group. This measure is also referred to as the probabilistic index [2] or probability of superiority, which will be cover in a separate post.
If there is no difference between the two arms, the probability will be close to 50%. Uncertainty intervals can be obtained via bootstrap or other means.
Loading required package: Rcpp
BuyseTest version 3.2.0
Table 1: Ranking criteria for desirability of outcome for PJI
Rank
Alive
Joint Function
Trt Success
QoL
1
Yes
Good
Yes
Tiebreaker based on EQ5D5L
2
Yes
Good
No
Tiebreaker based on EQ5D5L
3
Yes
Poor1
Yes
Tiebreaker based on EQ5D5L
4
Yes
Poor
No
Tiebreaker based on EQ5D5L
5
No
-
-
-
1Good joint function is based on thresholds related to patient reported success. A successful outcome at 12-months will be defined for knee PJI with an Oxford Knee Score (OKS) at 12 months of >36 or an improvement (delta) from baseline of >9 and for hip PJI as a Oxford Hip Score (OHS) of >38 or an improvement of >12 (35).
Consider a DOOR schema and ranking specification for prosthetic joint infection as per Table 1. Patients are assessed and assigned ranks based on how they align with the schema with the goal of differentiating the overall or global outcome of a patient state.
Below 100 people per group are simulated based on some hypothetical pair of distributions for the schema. The door probability is computed along with its confidence interval (by bootstrapping):
From above, the estimate for the door probability is 0.70 with a (bootstrapped) 95% CI of 0.63, 0.77.
The process is simple but the procedure itself does not readily admit to complex modelling. However, Follmann proposed using a logistic regression for the probability of superiority for each determinate pair of patients \(i\), \(j\) and covariate vectors \(\vec{z}_{ij} = \vec{z}_i - \vec{z}_j\) such that the parameters in the model correspond to the log-odds that a patient with \(\vec{z}_i\) has an outcome that is better than a patient with \(\vec{z}_j\)[3]. The presentation from Follmann is pretty convoluted and I lost patience with it. The exposition of probabilistic index models by De Schryver, which is analogous, if not equivalent, is much clearer and will be discussed separately, Probabilistic Index Models.
A shiny application for door analyses can be found at DOOR although it does not give any detail on the implementation of the methods used. Under the probability-based analysis tab, the overall door and then a decomposition based on each of the dichotomous door components is shown.
Scraping the source data of the site, you can at least recreate some of the statistics. For example, the door probabilities for the ARLG CRACKLE-I demo data as detailed in the door probability-based analysis tab, are replicated below for discharge from hospital:
Table 2: Colistin data from shiny application for DOOR
trt
door_num
door_txt
N
CAZ-AVB
1
Discharged home
6
CAZ-AVB
2
Alive in hosp, discharged not to home, no renal failure
17
CAZ-AVB
3
Alive in hosp, discharged not to home, renal failure
1
CAZ-AVB
4
Hospital death
2
Colistin
1
Discharged home
4
Colistin
2
Alive in hosp, discharged not to home, no renal failure
25
Colistin
3
Alive in hosp, discharged not to home, renal failure
which gives 0.56 aligning with the shiny app results.
Generalised pairwise comparisons
GPC is a related method and frankly it seems a bit better thought out than DOOR, but I am not sure that it is as popular [4]. The outcomes of interest are first ranked in terms of importance and the pairwise comparison is run progressively on each outcome for all pairs. For the ties under each outcome, the procedure moves on to the outcome that has the next highest priority and so on.
While GPC can be used to produce a range of summary measures, the original paper used net treatment benefit (NTB).
where \(n_{win} + n_{loss} + n_{tie}\) is typically equal to the total number of pairwise comparisons.
Unlike the DOOR approach, GPC allows for component level contribution and event level correlation. In contrast to the Win Ratio, the net treatment benefit incorporates ties.
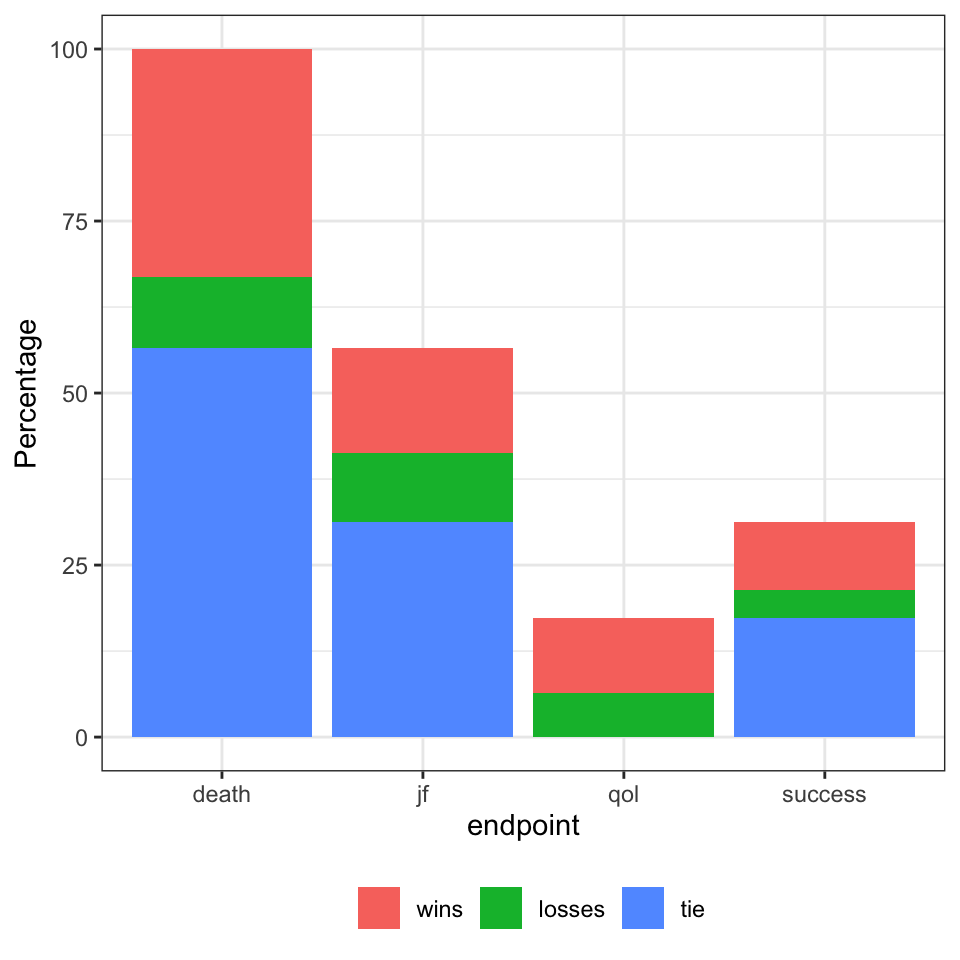
As an example, consider a situation where we have outcomes, as above, for death, joint function, treatment success and QoL. The procedure first runs pairwise comparisons for all units on death and the number of wins, draws and losses recorded, demonstration below.
# ntb on death is as follows:ntb <-numeric(4)names(ntb) <-c("death", "jf", "success", "qol")d_res <- d_all[, .N, keyby = death_res]d_res[, pct := N /nrow(d_all)]ntb["death"] <- (d_res[death_res ==1, N] - d_res[death_res ==-1, N]) /nrow(d_all)# for the ties on death, compute jf:d_res <- d_all[death_res ==0, .N, keyby = jf_res]d_res[, pct := N /nrow(d_all)]ntb["jf"] <- (d_res[jf_res ==1, N] - d_res[jf_res ==-1, N]) /nrow(d_all)# for comparisons on all pairs, don't condition:# d_res <- d_all[, .N, keyby = jf_res]# d_res[, pct := N / nrow(d_all)]# d_res# (d_res[jf_res == 1, N] - d_res[jf_res == -1, N]) / nrow(d_all)# for the ties on death and jf, compute success:d_res <- d_all[death_res ==0& jf_res ==0, .N, keyby = success_res]d_res[, pct := N /nrow(d_all)]ntb["success"] <- (d_res[success_res ==1, N] - d_res[success_res ==-1, N]) /nrow(d_all)# for the ties on death, jf and success, compute qol:d_res <- d_all[death_res ==0& jf_res ==0& success_res ==0, .N, keyby = qol_res]d_res[, pct := N /nrow(d_all)]ntb["qol"] <- (d_res[qol_res ==1, N] - d_res[qol_res ==-1, N]) /nrow(d_all)
Note that for all endpoints, we use the total number of pairwise comparisons as the denominator and not the number of ties left over from the previous outcome.
The resulting net treatment benefit reported on each outcome:
ntb
death jf success qol
0.2300 0.0527 0.0574 0.0455
Taking the cumulative sum, progresses from the effect of each component through to an overall effect:
cumsum(ntb)
death jf success qol
0.2300 0.2827 0.3401 0.3856
The NTB is absolute measure ranging from -1 to 1 with zero being no effect. It estimates the probability that a random unit on the expt arm will do better than a random unit on the control arm minus the probability that a random unit on the control arm will do better than a random unit on the expt arm. For example, if \(Pr(E>C) = 0.7\), then \(Pr(E<C) = 0.3\) and \(NTB = 0.7 - 0.3 = 0.4\).
You can compute the overall effect directly with the following:
The NTB is known to be the inverse of the number needed to treat, i.e. 1/ number of pt you need to trt to avoid one bad outcome. For large samples, inference can again be conducted via bootstrap. R provides the BuyseTest package that allows for stratification (beyond the implicit treatment level stratification).
ff1 <- trt ~bin(death, operator ="<0") +bin(jf) +bin(success) +cont(qol)f1 <-BuyseTest(ff1, data = d, trace =0)s_f1 <-summary(f1)
In the results, the totals, wins, loss and ties are presented as percentages rather than counts. For example, the total column effectively represents the proportion of pairs that carry over from one outcome to the next; for death there were 5660 pairs that carried over to joint function there were 3127 pairs that carried over to the treatment success outcome and so on. These can be visualised as: