where \(n\) is the sample size, \(\hat{p}\) is the observed sample proportion and \(z\) is the standard normal quantile (and typically set to \(\approx 2\)).
Say we had multiple estimates of the proportion, e.g. number of times we observe antimicrobial resistance out of the positive blood cultures we collected over the previous year. These estimates might come from differing hospitals and some might include repeat tests on individuals. This means that we have multiple levels of variation to deal with. One approach is to use a robust (sometimes call a Hubert White or sandwich) estimator for the standard errors.
This can be achieved by fitting a standard glm and then making an adjustment to the standard errors using the tools provided in the R sandwich package.
Simulate data for 500 patients from 10 sites, some patients having repeat measures.
# library(gee)library("geepack")# N unique pts on which we have multiple obs, each pt nested within one of# the 10 sitesN <-500N_site <-10p_site <-as.numeric(extraDistr::rdirichlet(1, rep(1, 10)))sites <-sample(1:N_site, N, replace = T, prob = p_site)d_pt <-data.table(id_pt =1:N,site =sort(sites))# number obs per pt - inflated here to make a pointn_obs <-rpois(N, 2)d <- d_pt[unlist(lapply(1:N, function(x){rep(x, n_obs[x])}))]d[, id_obs :=1:.N, keyby = id_pt]# about 60% (plogis(0.4)) resistant but with site and subject level# variability beyond the natural sampling variability due to varying # number of subjects per sitenu <-rnorm(N, 0, 0.5)# treat site as true fixed effectrho <-rnorm(N_site, 0, 0.7)d[, eta :=0.4+ rho[site] + nu[id_pt]]d[, y :=rbinom(.N, 1, plogis(eta))]d[, site :=factor(site)]d[, id_pt :=factor(id_pt)]p_obs <- d[, sum(y)/.N]# d[, .(y = sum(y), n = .N)]# distribution of frequency of observations on a pt# hist(d[, .N, keyby = id_pt][, N])
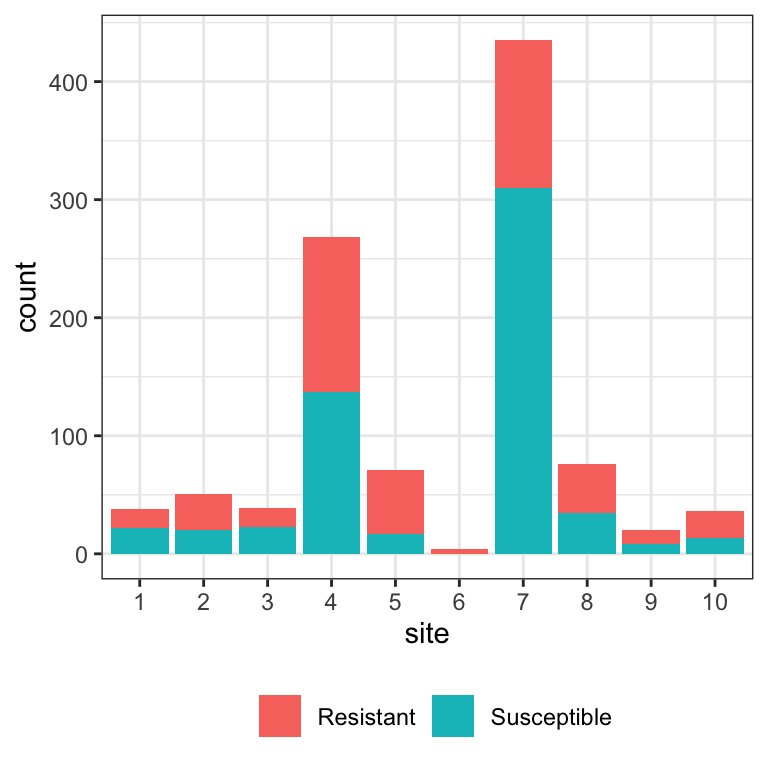
The raw numbers of observations at each site are shown in Figure 1.
A GLM with only an intercept term will give the same prediction as the observed proportion and we can calculate the naive estimate of uncertainty as:
# standard glm, not accounting for ptf1 <-glm(y ~1, family = binomial, data = d)predict(f1, type ="response")[1]
1
0.7467337
# get naive standard errorss_f1 <-summary(f1)$coef# model uncertainty naivelo_1 <-qlogis(p_obs)# se from intercept term, i.e. we are just looking at the 'average' or# typical pt, over which we would expect heterogeneityp_1_lb <-plogis(lo_1 -qnorm(0.975) * s_f1[1, 2])p_1_ub <-plogis(lo_1 +qnorm(0.975) * s_f1[1, 2])
We can use the sandwich estimator to adjuste for heterogeneity as:
# adjusted to account for heterogeneity due to site (we did not # adjust for site in the model) and repeat measure for ptsw_se <-sqrt(vcovCL(f1, cluster = d[, .(site, id_pt)], type ="HC1")[1,1])p_2_lb <-plogis(lo_1 -qnorm(0.975) * sw_se)p_2_ub <-plogis(lo_1 +qnorm(0.975) * sw_se)
f2 <-glmer(y ~ (1|site) + (1|id_pt), data = d, family = binomial)
Note that in the glmer model (with a non-linear link function) the predictions are first made on the link scale, averaged, and then back transformed. This means that the average prediction may not be exactly identical to the average of predictions.
You’ll note that the point estimate from the glmer deviates from the observed proportion. This can be for all of the following reasons:
The GLMM provides subject-specific estimates, conditional on the random effects.
GLMMs involve shrinkage, where estimates for groups with less data are pulled towards the overall mean.
Larger random effects can lead to bigger differences.
The GLMM estimate is a model-based estimate that accounts for the hierarchical structure of the data and provides a framework for inference.
In theory, a GEE could also be used but in R the GEE framework is not particularly well set up for multiple levels of clustering.
# Model based adjusting for site.sprintf("%.4f (%.4f, %.4f)", p_obs, p_1_lb, p_1_ub)
[1] "0.7467 (0.7188, 0.7728)"
# Adjusted - account for heterogeneity due to site (we did not # adjust for site) and repeat measure for ptsprintf("%.4f (%.4f, %.4f)", p_obs, p_2_lb, p_2_ub)
[1] "0.7467 (0.6330, 0.8344)"
# Finally a random effects modelavg_predictions(f2, re.form =NA, type ="link")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
1.04 0.291 3.57 <0.001 11.4 0.468 1.61
Type: link
avg_predictions(f2, re.form =NA, type ="response")
Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0.739 0.0563 13.1 <0.001 128.4 0.628 0.849
Type: response